If you have a high-performance computer with a capable Graphics card, then you can download the Whisper AI setup file from GitHub.
If you are using a PC that does not have a dedicated Graphics card, then the best way to use Whisper AI is through Google Colaboratory. This allows you to run the codes directly in your Web browser. Watch the video guide on how to run Whisper AI in Google Colaboratory.
If you are using a PC that does not have a dedicated Graphics card, then the best way to use Whisper AI is through Google Colaboratory. This allows you to run the codes directly in your Web browser. Watch the video guide on how to run Whisper AI in Google Colaboratory.
WhisperAI is a cutting-edge, open-source automatic speech recognition (ASR) system developed in Python by the AI research and deployment company called Open AI. It boasts a high level of robustness and accuracy in English speech recognition, approaching human-level performance.
Whisper AI excels in providing high-quality transcripts with proper capitalization and punctuation, including English transcription, non-English transcription, and non-English to English translation. Additionally, it has the ability to eliminate background noise to improve transcript quality.
The system was trained on a massive and diverse dataset of 680,000 hours of multilingual and multitask supervised data, collected from various sources on the web, without being fine-tuned to any specific task.
Approximately one-third of Whisper's audio dataset is non-English, and it has been trained to transcribe the original language or translate it to English.
Whisper offers five different model sizes, with four English-only versions, providing users with options to balance speed and accuracy. The available models and their approximate memory requirements and relative speeds are listed below.
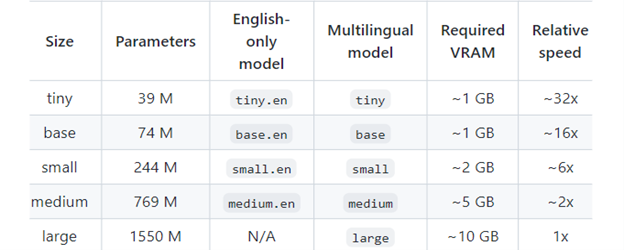
Table Source: Whisper Github Readme
The audio input is decoded and saved into various file formats, including JSON, SRT, TSV, TXT, and VTT, which can be downloaded for further use.
Whisper AI excels in providing high-quality transcripts with proper capitalization and punctuation, including English transcription, non-English transcription, and non-English to English translation. Additionally, it has the ability to eliminate background noise to improve transcript quality.
The system was trained on a massive and diverse dataset of 680,000 hours of multilingual and multitask supervised data, collected from various sources on the web, without being fine-tuned to any specific task.
Approximately one-third of Whisper's audio dataset is non-English, and it has been trained to transcribe the original language or translate it to English.
Whisper offers five different model sizes, with four English-only versions, providing users with options to balance speed and accuracy. The available models and their approximate memory requirements and relative speeds are listed below.
Table Source: Whisper Github Readme
The audio input is decoded and saved into various file formats, including JSON, SRT, TSV, TXT, and VTT, which can be downloaded for further use.
Whisper AI is a useful tool for the legal field, as it can transcribe court judgements, case reports, and digests.
If you want to install Whisper AI on your computer, a high-end Graphics card is required to fully utilize its capabilities.
Some language codes may produce errors during transcription, particularly for Indian languages other than Tamil and Hindi. Transcribing and translating materials in vernacular languages with specialized jargon may prove challenging with Whisper AI.
Some language codes may produce errors during transcription, particularly for Indian languages other than Tamil and Hindi. Transcribing and translating materials in vernacular languages with specialized jargon may prove challenging with Whisper AI.
Whisper's performance varies significantly among different languages. Languages such as Spanish, Italian, English, Portuguese, German, Japanese, Russian, Polish, French, Catalan, Dutch, Indonesian, and Turkish have relatively low Word Error Rate (WER). A WER of 5-10% is considered good quality and ready for use, while a WER of 20% is considered acceptable but may require additional data training. Unfortunately, all Indian languages have a WER of over 20%.